Kaggle 0 手写数字识别器的探索
最近打算开始玩Kaggle,作为入门选了一个入门级的任务Digit-Recognizer。正好在翻《机器学习实战》的时候看到可以用KNN做图像识别,于是就打算用KNN来做一个手写数字的识别器(9.13:现在要换成CNN来做了)。这也算是我第一次应用机器学习来解决比较实际的问题。此篇作为一个类似于项目日志的东西,在这个项目完成之前,应该会一直更新。
9.11
没看书自己实现了一下KNN,算法本身也没什么复杂的,但是实现起来还是费了一番不小的功夫,动手能力还需增强啊…
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@author: drapor
"""
import pandas as pd
import numpy as np
print('Importing the data...')
train_set = pd.read_csv('train.csv')
pixel = train_set.iloc[:,1:785]
label = train_set.iloc[:,0]
test_set = pd.read_csv('test.csv')
r = []
for t in range(len(test_set)):
print('%d/28000' % (t+1))
a = np.array(test_set.loc[t])
d = []
for i in range(len(train_set)):
b = np.array(pixel.loc[i])
d.append(np.dot((a-b).T,(a-b)))
k = list(zip(d,range(len(d))))
k.sort()
m = []
for i in k[:10]:
m.append(label.loc[i[1]])
r.append(sum(m)/10)跑了几个试了试,K选了10,有一些误差,不过效果看起来还可以。但是全量数据一起跑的时候就发现,完成任务需要的时间非常久,大概至少需要三十个小时。这当然是不能接受的,得想办法改进才行。目前初步的打算是用多进程,应该可以明显地缩短完成任务所需的时间。
9.12
昨天请教了公司的组长之后得知,还可以用Deep Learning中的Pooling来降低计算的复杂度,但还是想先上多线程看看。经过一个晚上和半个上午的研究探索,终于成功地让任务以多进程的方式跑起来了。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Description:
kaggle 0
@author: drapor
"""
import pandas as pd
import numpy as np
import multiprocessing
import os
#import matplotlib.pyplot as plt
def processing(test_set):
s = []
print("Running... pid:" + str(os.getpid()))
for idx, df in test_set.iterrows():
print('%d/28000, pid %s' % (idx, os.getpid()))
a = np.array(df)
d = []
for i in range(42000):
b = np.array(pixel.iloc[i])
d.append(np.dot((a-b).T,(a-b)))
k = list(zip(d,range(len(d))))
k.sort()
m = []
for i in k[:10]:
m.append(label.loc[i[1]])
s.append([idx,sum(m)/10])
return s
if __name__ == '__main__':
print('Importing the data...')
train_set = pd.read_csv('train.csv')
pixel = train_set.iloc[:,1:785]
label = train_set.iloc[:,0]
#plt.imshow(test.reshape(28,28), cmap=plt.cm.gray)
test_set = pd.read_csv('test.csv')
pool = multiprocessing.Pool(processes = 16)
r = []
for i in range(16):
train = test_set.loc[1750*i:1750*(i+1)-1]
r.append(pool.apply_async(processing,(train,)))
pool.close()
pool.join()
result = []
for i in r:
for j in i.get():
result.append(j)
result.sort()
with open('result.csv',"w") as f:
for i in result:
f.writelines(str(i[0]+1)+','+str(round(i[1]))[:-2]+'\n')为了能够快速地完成任务,我又去AWS上租了一个c4.4xlarge,配置是16 vCPU, 2.9 GHz, Intel Xeon E5-2666v3, 30 GiB 内存,在上面把任务分成16个进程进行计算。即便如此,整个任务还是花费了大概三四个小时的时间,但总算最后还是成功地跑出来了。
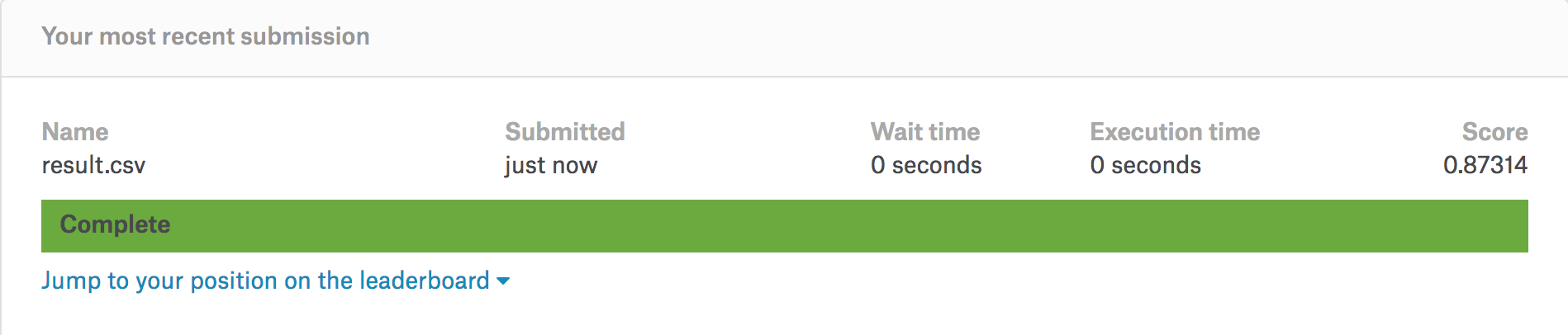
将结果按照要求稍微整理一下就可以提交了,初次提交的分数是0.87314,预料之中。虽然准确率看起来还可以,但这个成绩在这项竞赛中的排名是1534/1625,非常的惨淡,不过这也说明改进的空间还很大。之后考虑用Pooling试试。
9.13
今天发现其实Pooling并不是一种可以提高精度的办法,只是一种可以降低计算复杂度的方法,如果原算法的精度本身就不高的话,Pooliing之后同样也不高,组长建议我改用CNN。我想了一下,就算调整K的值重新跑一次可能不会使准确率有明显的提升,Google了一下发现大家用KNN做手写识别,精度可能也就追求到0.8。嗯……这两天探索一下Tensorflow+CNN(之前只是知道,并没有深入了解过),尝试用这种方式解决这个问题。