Machine Learning Notes 07
What should we do if we have a bad predictions?
The following options may be feasible:
- Get more training examples;
- Try smaller sets of features;
- Try getting additional features;
- Try adding polynomial features (increasing degree of polynomial);
- Try decreasing \(\lambda\);
- Try increasing \(\lambda\);
So we can take a kind of test called machine learning diagnostic to insight what is/isn’t working with a learning algorithm, and gain guidance as to how best to improve its performance. It may take time to implement, but doing so can be vary good use of your time.
Evaluating a hypothesis
To evaluating whether a hypothesis is good or bad (and we don’t have extra test set), we can divide our training set at first to two parts (usually according to 7/3 proportion), and one for training, the other for testing, which helps us to avoid over fitting (perform on training set well, but bad on new examples not in training set)
Model Selection
Take linear regression as a example, we use \(h_{\theta}(x) = \theta_0 +\theta_1 x + \theta_2 x^2 + \cdots\) as our hypothesis function, and we can add the degree of polynomial to make our hypothe/.sis better, but it may brings the over fitting problem, so we need to find out the best degree.
To achieve so, we can compute the \(J_{test}\)(cost of different degrees \(d\) on test set), and choose the best \(d\), but it’s only fit to the test set. So we divide the data set into three parts:
- training set (60% usually)
- cross validation set (20% usually)
- test set (20% usually)(check if the combo of \(\theta\) and \(\lambda\) has a good generalization of the problem, avoiding over fitting)
and three kinds of cost function is \(J_{train}\), \(J_{cv}\), \(J_{test}\).
Then for different \(d(d=1, 2, 3, \cdots)\), minimize \(J(\theta)\) with \(J_{train}\) and \(J_{test}\), then compute the \(J_{cv}\) for each \(d\). We choose \(d\) who has the lowest \(J_{cv}\), and that.s how we do the model selection.
Bias vs. Variance
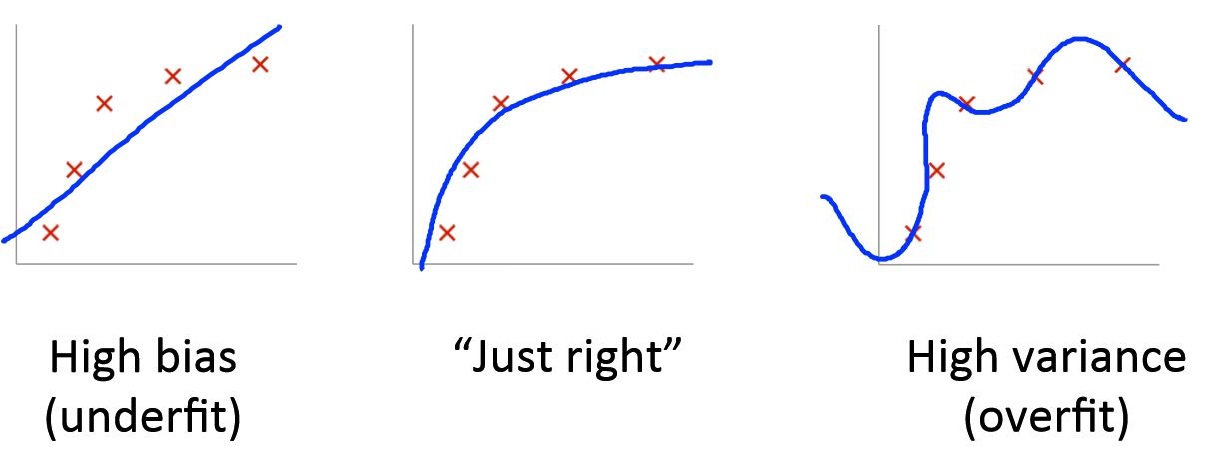
Diagnosing bias vs. variance
- If \(J_{train}\) is high and \(J_{cv}\approx J_{train}\), we can tell it’s a bias problem;
- If \(J_{train}\) is low and \(J_{cv}\gg J_{train}\), we can tell it’s a variance problem;
About regularization
As we know, appropriate \(\lambda\) (regularization parameter) can help to prevent over fitting, but when the \(\lambda\) is too large or too small. it won’t work as so:
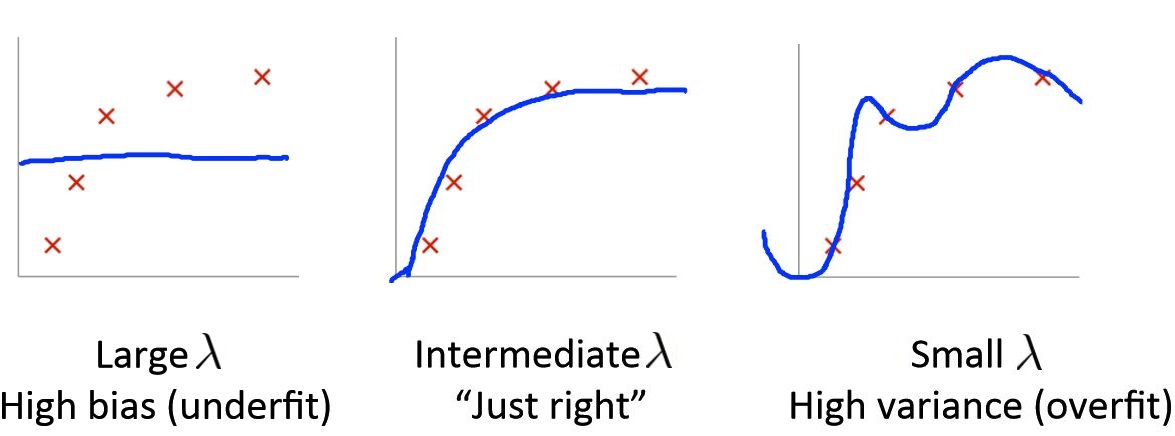
So choosing appropriate value of \(\lambda\) is very necessary.
We can try different \(\lambda\), minimize \(J(\theta)\), then compute \(J_{cv}\) (like what we do the model selection), and we can finf the best \(\lambda\).
Learning Curves
The learning curves describe the relationship of \(m\)(training set size) and error(\(J_{cv},J_{train}\)), it’s look like:
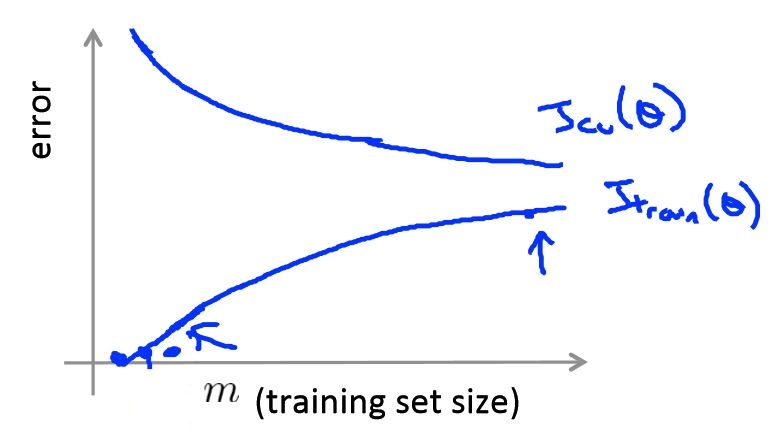
And if the algorithm is suffering from high bias, the learning curve is look like:
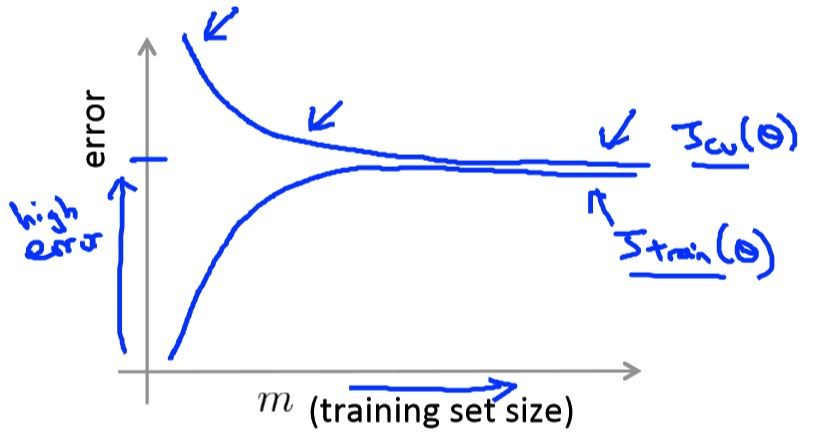
We can see from the graph that the increasing \(m\) doesn’t help to lower the bias, so we can conclude that getting more training data will not help to solve high-bias problem.
While if the algorithm is suffering from high variance, the learning curve is look like:

From the graph we can see that there is a gap between \(J_{cv}\) and \(J_{train}\), and as \(m\) increasing, the gap diminishes and the bias is also decreasing. So we can conclude that getting more training data is helpful to solve the high-variance problem.