Machine Learning Notes 05
Overfitting
Overfitting would cause the modle to perform poorly, like this:
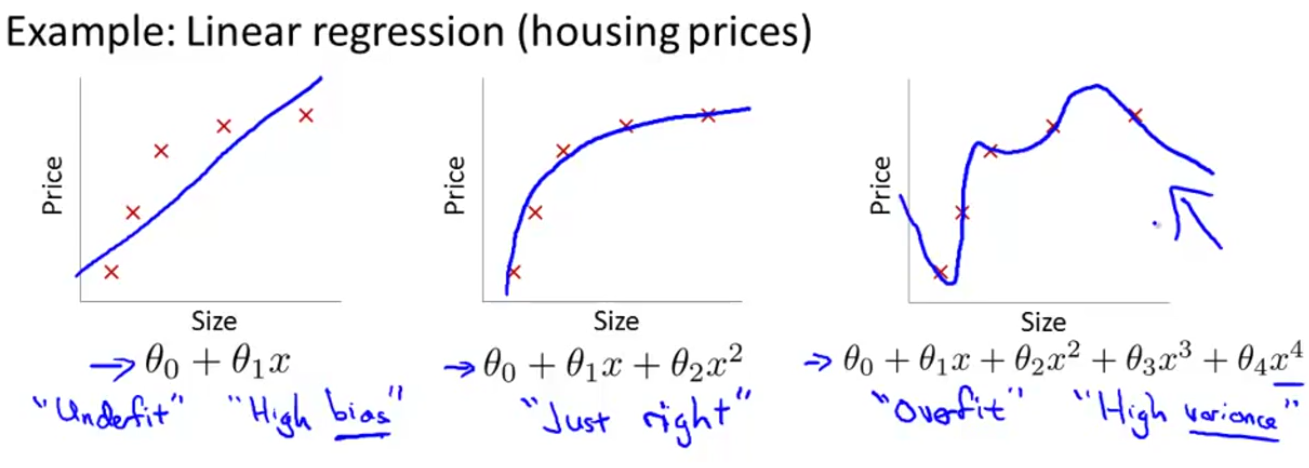
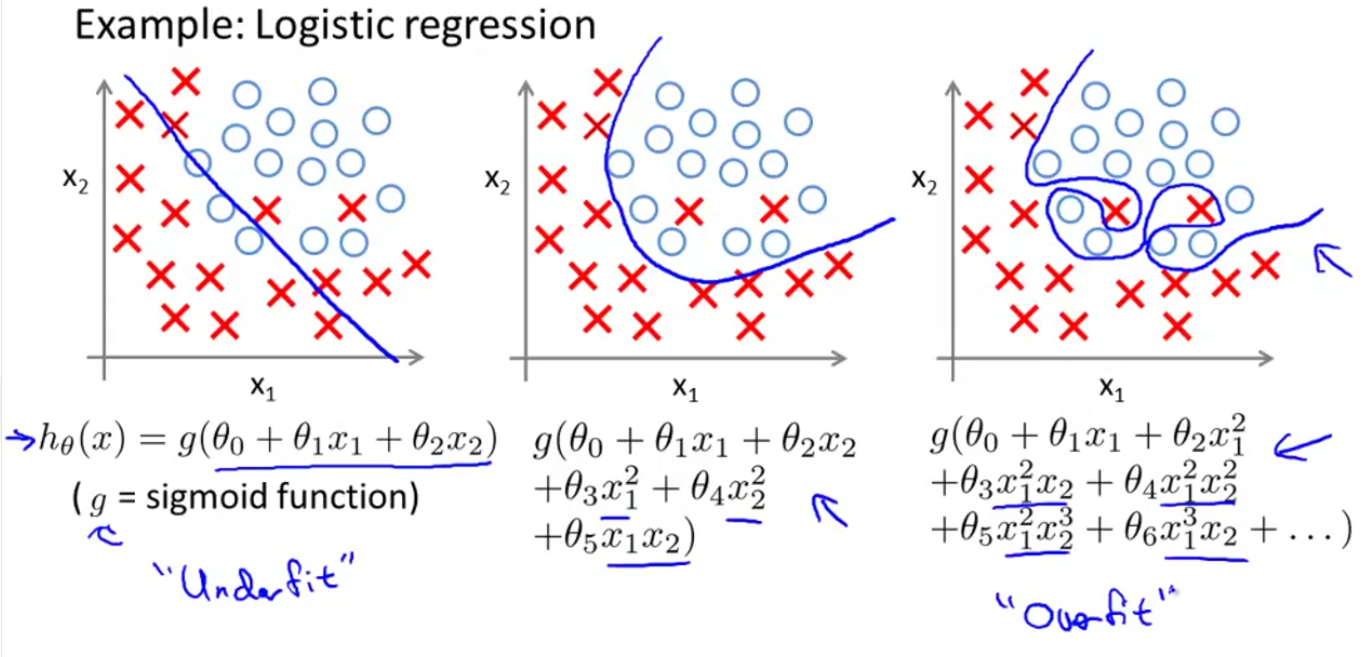
As above, plotting the hypothesis could be one way to try to decide what degree polynomial to use, but that doesn’t always work. Sometims we have too many features which cause that it’s difficult to visulize. And if we have a lot of features and very little training data, then overfitting can become a problem.
Two options to solve
1.Reduce the number of features
Manually select which features to keep or throw out;
Model selection algorithm (help ue to decide which features to keep or throw out automatically);
Disadvantages: Reduce some information about the problem.
2.Regularization
Keep all the features, but reduce magnitude/values of parameters \(\theta_{j}\). Works well when we have a lot of features, each of which contributes a bit to predicting \(y\).
So we can see regularization is a better choice mostly.
See the cost functinon
- First, consider this. If our hypothesis is like this:
\(\theta_{0} + \theta_{1}x + \theta_{2}x^{2} + \theta_{3}x^3 + \theta_{4}x^4\)
and if we penalize and make \(\theta_{3}\) and \(\theta_{4}\) really small, it means that \(\theta_{3}\approx0,\theta_{4}\approx0\), that is like as if we ’re getting rid of these two terms, then we would find that \(\theta_{0} + \theta_{1}x + \theta_{2}x^{2} + \theta_{3}x^3 + \theta_{4}x^4\approx\theta_{0} + \theta_{1}x + \theta_{2}x^{2} \)
Regularization
“…having smaller values of the parameters corresponds to usually smoother functions as well for the simpler. And which are therefore, also, less prone to overfitting. ” What we should do is to modify the cost function to shrink all of the parameters like this: \(J(\theta)=\frac{1}{2m}\sum_{i=1}^{n}(h_{\theta}(x^{(i)})-y^{(i)})^{2} + {\color{Blue} {\lambda\sum_{i=1}^{m}\theta_{j}^{2}}}\)
And the blue terms is called regularization terms, \(\lambda\) is called regularization parameters which is used to trade off between two different goals:
- \(\sum(h_{\theta}(x^{(i)})-y^{(i)})^{2}\) fit well
- \(\sum{\theta_{j}^{2}}\) keep the parameters small
By the way, we don’t penalize \(\theta_{0}\) by convention. Besides, about the regularization parameters \(\lambda\), if \(\lambda\) is too large, it would cause underfitting, and if \(\lambda\) is too small, it may cause the useless regularization.
Regularized linear regression
- Gradient descent:
Old:
Repeat{
\(\theta_{j}:=\theta_{j}-\alpha\frac{1}{m}\sum_{i=1}^{n}(h_{\theta}(x^{(i)})-y^{(i)})x_{j}^{(i)}\:(j=0,1,2,3,\cdots,n)\).
}
New:
Repeat{
\({\color{Blue} {\theta_{0}:=\theta_{0}-\alpha\frac{1}{m}\sum_{i=1}^{n}(h_{\theta}(x^{(i)})-y^{(i)})x_{0}^{(i)}}}\)
\({\color{Blue} {\theta_{j}:=\theta_{j}-\alpha\frac{1}{m}\sum_{i=1}^{n}(h_{\theta}(x^{(i)})-y^{(i)})x_{j}^{(i)}:(j=1,2,\cdots,n)}}{\color{Red} {+\frac{\lambda}{m}\theta_{j}}}\)
}
Regularization logistic regression
Cost function \(J(\theta)=-ylog(h_{\theta}(x))-(1-y)log(1-h_{\theta}(x)){\color{Blue} {+\frac{\lambda}{2m}\sum_{j=1}^{n}\theta_{j}^{2}}}\)
Repeat{
\({\color{Blue} {\theta_{0}:=\theta_{0}-\alpha\frac{1}{m}\sum_{i=1}^{n}(h_{\theta}(x^{(i)})-y^{(i)})x_{0}^{(i)}}}\)
\(\theta_{j}:=\theta_{j}-\alpha\frac{1}{m}\sum_{i=1}^{n}(h_{\theta}(x^{(i)})-y^{(i)})x_{j}^{(i)}:(j=1,2,\cdots,n){\color{Red} {+\frac{\lambda}{m}\theta_{j}}}\)
}
Remember that \(h_{\theta}(x)=\frac{1}{1+e^{-\theta^{T}x}}\)